Advanced RAG: Enhancing Retrieval Efficiency through Rerankers using LlamaIndex🦙
Using Open Source LLM Zephyr-7b-alpha and Cohere and BGE Embeddings
Welcome to the Advanced RAG 📚Learning Series!
Dive deeper into the fascinating world of Retrieval-Augmented Generation with this comprehensive series of articles. This series delves into cutting-edge techniques and strategies to elevate your understanding and mastery of RAG applications. Explore the following articles to enhance your skills and Stay tuned 🔔 for more articles in this series as we continue to delve deeper into the world of Advanced RAG and unlock its boundless potential.
Don’t miss out on any discoveries! Bookmark🏷️ this article and check back often for the latest installments in this exciting learning series.
Topics covered so far:
- Optimizing Retrieval with Additional Context & MetaData using LlamaIndex
- Enhancing Retrieval Efficiency through Rerankers using LlamaIndex (you are here!)
- Query Augmentation for Next-Level Search using LlamaIndex
- Smart Tracking and Debugging of Document Changes using LlamaIndex

Advanced RAG architectures need to implement dynamic retrieval. A big downside with naive top-k RAG is the fact that retrieval is static.
- It always retrieves a fixed number (k) regardless of the query
- What if the query requires more context (e.g. summarization) or less context?
Instead, you can implement dynamic retrieval in two conceptual stages:
- Pre-retrieval: Decide which retriever is suitable for the use case
- Post-retrieval: Decide whether to rerank or filter results
This is super important to dynamically prune irrelevant context. It allows us to set a big top-k but still increase precision.
This blog explains one of the key concepts in building a robust recommendation system focusing on optimizing the retrieval process. Here, we will focus on LLM-powered retrieval and reranking to improve how we find documents.
When we talk about LLM-powered retrieval, we mean a way to find documents in a smarter way than the usual method using embeddings.
It helps to create enhancements to document retrieval beyond naive top-k embedding-based lookup and returns more relevant documents than embedding-based retrieval.
But, it comes with a tradeoff of much higher latency and cost. Hence, to balance things out: we start by quickly finding documents using the usual embedding-based retrieval, and then, we use the smarter LLM-powered method to make sure the best documents show up first as a reranking step. It’s like doing a fast search first and then doing a deeper, more accurate search to get the best results.
Why Re-ranking?
Re-ranking is a step in the retrieval process where the initially retrieved results are further sorted, refined, or reordered based on certain criteria to improve their relevance or accuracy.
Here’s an example: Imagine you’re searching for information about penguins. When you enter your search query, the system quickly brings up several articles about different types of penguins. These results are the first pass, retrieved based on general relevance.
Now, let’s say the first few articles are about “Penguins in Antarctica,” but what you really wanted was information about “Penguins in Zoo Habitats.” Re-ranking comes in at this stage. The system can use additional methods, perhaps considering user behavior, specific keywords, or more sophisticated algorithms, to reorder these search results. It might move the articles about zoo habitats higher in the list, pushing down those about Antarctica. This step ensures that the most relevant or helpful information appears at the top, making it easier for you to find what you’re looking for.
In essence, re-ranking fine-tunes the initially retrieved results, providing a more tailored and relevant set of documents or information based on specific criteria or user preferences.
What’s wrong with embedding-based retrieval?
There are numerous advantages to using embedding-based retrieval:
- It performs rapid computations of dot products and doesn’t necessitate any model calls during query time.
- Even though not flawless, embeddings can reasonably encode the document and query semantics. There’s a subset of queries where embedding-based retrieval yields highly pertinent outcomes.
However, despite these merits, embedding-based retrieval can sometimes lack precision and return irrelevant context related to the query. This, in turn, diminishes the overall quality of the RAG system, regardless of the LLM’s quality.
This challenge isn’t new and has been tackled in recommendation systems through a two-stage process. The initial stage utilizes embedding-based retrieval with a high top-k value, emphasizing recall over precision.
Subsequently, the second stage employs a slightly more computationally intensive process, focusing on higher precision and lower recall to rerank the initially retrieved candidates.
Implementation(Open Source LLM and Embedding)
Essentially, this method employs the LLM to determine the relevance of specific documents or nodes to a provided query. The input prompt includes a group of potential documents, and the LLM’s role involves both identifying the pertinent set of documents and assessing their relevance using an internal metric.
We will use Open Source LLM zephyr-7b-alpha and embedding hkunlp/instructor-large
Let’s implement it step-by-step:
- Load Data — Before your chosen LLM can act on your data you need to load it. The way LlamaIndex does this is via data connectors, also called
Reader. Data connectors ingest data from different data sources and format the data intoDocumentobjects. ADocumentis a collection of data (currently text, and in the future, images, and audio) and metadata about that data.
PDFReader = download_loader("PDFReader")
loader = PDFReader()
docs = loader.load_data(file=Path("QLoRa.pdf"))2. Chunking- We will create nodes by splitting the text into a chunk size of 512. A Node is the atomic unit of data in LlamaIndex and represents a “chunk” of a source Document. Nodes contain metadata and relationship information with other nodes.
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(docs)3. Open Source LLM and Embedding — We will use Open Source LLM zephyr-7b-alpha and will quantify it for memory and computation. This should run on a T4 GPU in the free tier on Colab.
In this example, we will use hkunlp/instructor-large. This is an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) by simply providing the task instruction, without any finetuning. Instructor👨 ranks at #14 on the MTEB leaderboard!
from google.colab import userdata
# huggingface and cohere api token
hf_token = userdata.get('hf_token')
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
def messages_to_prompt(messages):
prompt = ""
for message in messages:
if message.role == 'system':
prompt += f"<|system|>\n{message.content}</s>\n"
elif message.role == 'user':
prompt += f"<|user|>\n{message.content}</s>\n"
elif message.role == 'assistant':
prompt += f"<|assistant|>\n{message.content}</s>\n"
# ensure we start with a system prompt, insert blank if needed
if not prompt.startswith("<|system|>\n"):
prompt = "<|system|>\n</s>\n" + prompt
# add final assistant prompt
prompt = prompt + "<|assistant|>\n"
return prompt
# LLM
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-alpha",
tokenizer_name="HuggingFaceH4/zephyr-7b-alpha",
query_wrapper_prompt=PromptTemplate("<|system|>\n</s>\n<|user|>\n{query_str}</s>\n<|assistant|>\n"),
context_window=3900,
max_new_tokens=256,
model_kwargs={"quantization_config": quantization_config},
# tokenizer_kwargs={},
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
messages_to_prompt=messages_to_prompt,
device_map="auto",
)
# Embedding
embed_model = HuggingFaceInstructEmbeddings(
model_name="hkunlp/instructor-large", model_kwargs={"device": DEVICE}
)4. Configure Index and Retriever — First, we will be setting up the ServiceContextobject and will be using it to construct an index and query.
An Index is a data structure composed of Document objects, designed to enable querying by an LLM. This means creating a data structure that allows for querying the data. For LLMs this nearly always means creating vector embeddings, and other metadata strategies to find contextually relevant data.
Vector store indexes are the most common and simple to use. Allowing answering a query over a large corpus of data. Querying a vector store index involves fetching the `top-k` most similar Nodes, and passing those into the `Response Synthesis` module.
Vector Store Index embeds your documents. It takes your Documents and splits them up into Nodes. It then creates vector embeddings of the text of every node, ready to be queried by an LLM.
When you want to search your embeddings, your query is itself turned into a vector embedding, and then a mathematical operation is carried out by VectorStoreIndex to rank all the embeddings by how semantically similar they are to your query.
Top K Retrieval Once the ranking is complete, VectorStoreIndex returns the most-similar embeddings as their corresponding chunks of text. The number of embeddings it returns is known as k, so the parameter controlling how many embeddings to return is known as `top_k`. This whole type of search is often referred to as “top-k semantic retrieval” for this reason.
# ServiceContext
service_context = ServiceContext.from_defaults(llm=llm,
embed_model=embed_model
)
# index
vector_index = VectorStoreIndex(
nodes, service_context=service_context
)
# configure retriever
retriever = VectorIndexRetriever(
index=vector_index,
similarity_top_k=10,
service_context=service_context)You can follow along with this notebook:
5. Initialize Re-rankers
We will compare the performance of our Retrieval with 3 rerankers:
# Define all embeddings and rerankers
RERANKERS = {
"WithoutReranker": "None",
"CohereRerank": CohereRerank(api_key=cohere_api_key, top_n=5),
"bge-reranker-base": SentenceTransformerRerank(model="BAAI/bge-reranker-base", top_n=5),
"bge-reranker-large": SentenceTransformerRerank(model="BAAI/bge-reranker-large", top_n=5)
}6. Retrieval Comparisons
A retriever defines how to efficiently retrieve relevant context from an index when given a query. Your retrieval strategy is key to the relevancy of the data retrieved and the efficiency with which it’s done. The most common type of retrieval is “top-k” semantic retrieval, but there are many other retrieval strategies.
Node Postprocessors: A node postprocessor takes in a set of retrieved nodes and applies transformations, filtering, or re-ranking logic to them. Node Post-processors are most commonly applied within a query engine after the node retrieval step and before the response.
Let’s create some helper functions to perform our task:
# helper functions
def get_retrieved_nodes(
query_str, reranker
):
query_bundle = QueryBundle(query_str)
retrieved_nodes = retriever.retrieve(query_bundle)
if reranker != "None":
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
else:
retrieved_nodes
return retrieved_nodes
def pretty_print(df):
return display(HTML(df.to_html().replace("\\n", "<br>")))
def visualize_retrieved_nodes(nodes) -> None:
result_dicts = []
for node in nodes:
node = deepcopy(node)
node.node.metadata = None
node_text = node.node.get_text()
node_text = node_text.replace("\n", " ")
result_dict = {"Score": node.score, "Text": node_text}
result_dicts.append(result_dict)
pretty_print(pd.DataFrame(result_dicts))Let’s visualize the result for our query:
query_str = "What are the top features of QLoRA?"
# Loop over rerankers
for rerank_name, reranker in RERANKERS.items():
print(f"Running Evaluation for Reranker: {rerank_name}")
query_bundle = QueryBundle(query_str)
retrieved_nodes = retriever.retrieve(query_bundle)
if reranker != "None":
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
else:
retrieved_nodes
print(f"Visualize Retrieved Nodes for Reranker: {rerank_name}")
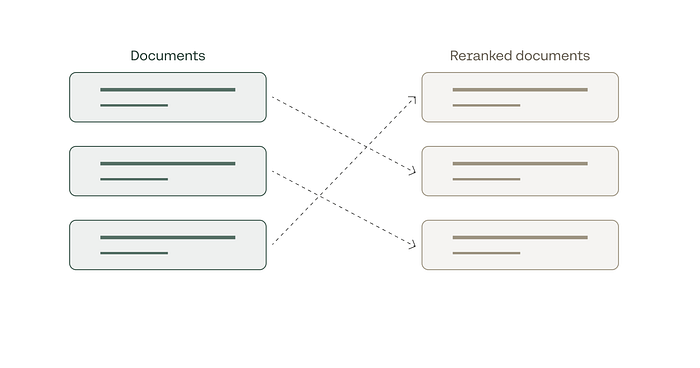
visualize_retrieved_nodes(retrieved_nodes)- No reranker — The top node has a similarity score of 0.87. It’s our baseline score.
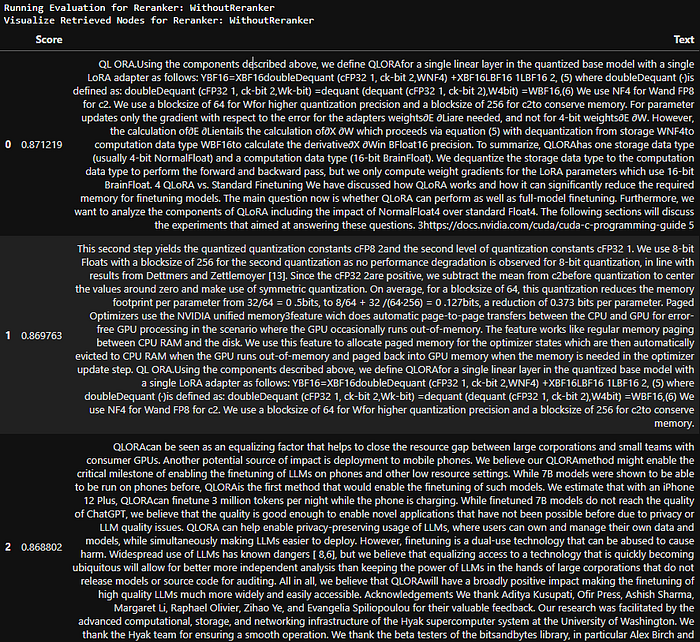
- CohereRerank — The top node has a similarity score of 0.988. See, how using the Cohere reranker has improved the quality of our retrieved nodes.
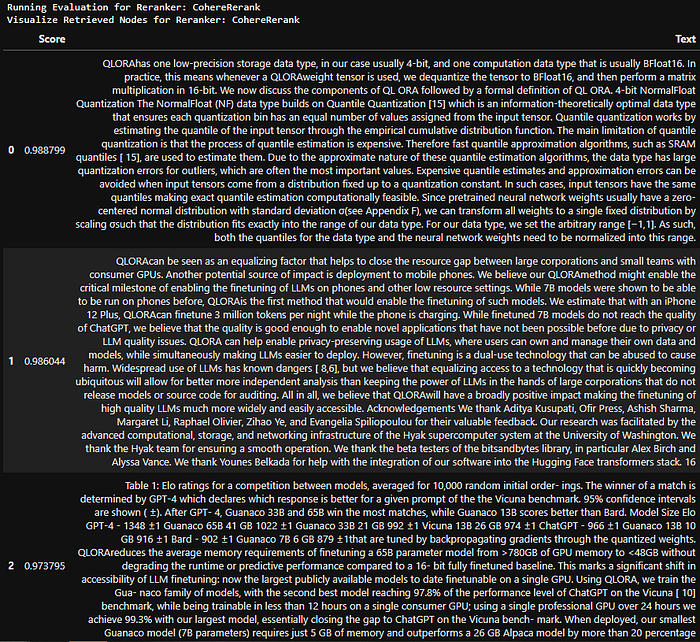
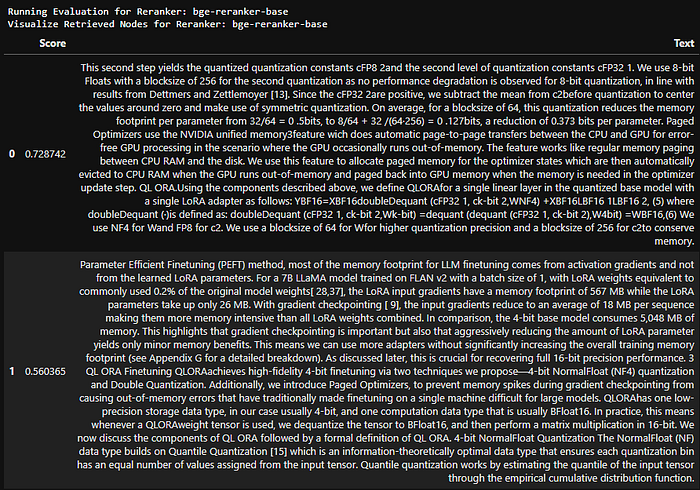
- bge-reranker-base — The top node has a similarity score of 0.72. It didn't work up to the mark. Maybe, we should try it with a different embedding model and compare results.
Evaluation
Now, we will use RetrieverEvaluator to evaluate the quality of our Retriever.
We define various evaluation metrics, such as hit-rate and MRR, which assess the quality of retrieved results against the ground-truth context for each specific question. To simplify the creation of the evaluation dataset initially, we can depend on synthetic data generation methods.
- MRR stands for Mean Reciprocal Rank and is a rank-aware relevance score in the first 10 results of a ranking. The reciprocal rank of a query response is the multiplicative inverse of the rank of the first correct answer: 1 for first place, 1/2 for second place, and 1/n for the nth place. The mean reciprocal rank is the average of the reciprocal ranks of results for a sample of queries.
- Hit Rate measures the proportion or percentage of queries for which the retrieved results contain at least one relevant item from the ground truth. For instance, imagine a search engine returning a list of documents in response to a user’s query. The ground truth here refers to the known relevant documents for that query, typically determined by human judgment or labeled data. The hit rate calculates how often the search results include at least one of these relevant documents.
Build an Evaluation dataset of (query, context) pairs
We can manually curate a retrieval evaluation dataset of questions + node id’s. Llamaindex offers synthetic dataset generation over an existing text corpus with our generate_question_context_pairs function. This uses the LLM to auto-generate questions from each context chunk. Refer here.
Here we build a simple evaluation dataset over the existing text corpus. We will use Zephr-7B LLM to generate Question-Context Pairs.
The returned result is a EmbeddingQAFinetuneDataset object (containing queries, relevant_docs, and corpus).
# Prompt to generate questions
qa_generate_prompt_tmpl = """\
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge.
generate only questions based on the below query.
You are a Professor. Your task is to setup \
{num_questions_per_chunk} questions for an upcoming \
quiz/examination. The questions should be diverse in nature \
across the document. The questions should not contain options, not start with Q1/ Q2. \
Restrict the questions to the context information provided.\
"""
# Evaluator
qa_dataset = generate_question_context_pairs(
nodes, llm=llm, num_questions_per_chunk=2, qa_generate_prompt_tmpl=qa_generate_prompt_tmpl
)# helper function for displaying results
def display_results(reranker_name, eval_results):
"""Display results from evaluate."""
metric_dicts = []
for eval_result in eval_results:
metric_dict = eval_result.metric_vals_dict
metric_dicts.append(metric_dict)
full_df = pd.DataFrame(metric_dicts)
hit_rate = full_df["hit_rate"].mean()
mrr = full_df["mrr"].mean()
metric_df = pd.DataFrame({"Reranker": [reranker_name], "hit_rate": [hit_rate], "mrr": [mrr]})
return metric_dfLlamaindex offers a function to run a RetrieverEvaluator over a dataset in batch mode.
query_str = "What are the top features of QLoRA?"
results_df = pd.DataFrame()
# Loop over rerankers
for rerank_name, reranker in RERANKERS.items():
print(f"Running Evaluation for Reranker: {rerank_name}")
query_bundle = QueryBundle(query_str)
retrieved_nodes = retriever.retrieve(query_bundle)
if reranker != "None":
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
else:
retrieved_nodes
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
current_df = display_results(rerank_name, eval_results)
results_df = pd.concat([results_df, current_df], ignore_index=True)Results
- WithoutReranker: This provides the baseline performance for each embedding.
- CohereRerank: Provided the best results among all others.
- bge-reranker-base: Less accurate results than CohereRerank. Maybe the selected embedding model is not effective for this reranker.
- bge-reranker-large: Poor results than bge-reranker-base. Maybe the selected embedding model is not effective for this reranker.
The results indicate the importance of rerankers in optimizing the retrieval process. Particularly, CohereRerank has showcased its ability to elevate any embedding to the next level.
Summary
In this blog post, we’ve demonstrated performance comparison across multiple rerankers using LlamaIndex, which has improved retrieval performance metrics.
Additionally, we can improve the retrieval process by performing experiments (not limited to) :
- Employ various embedding models
- Employ various reranker models.
- Select additional evaluation metrics like `Accuracy` and `NDCG` (Normalized Discounted Cumulative Gain) etc.
- Select various other LLMs
Conclusion
Selecting the appropriate embedding for the initial search holds utmost importance; even the most effective reranker can’t compensate for poor basic search outcomes (bge-rerankers in our case).
Maximizing retriever performance depends on discovering the optimal blend of embeddings and rerankers. This continues to be an active research area to identify the most effective combinations.
Refer to the complete code on Github:
To refer to other advanced RAG methods, refer to this repo:
Thank you for reading this article, I hope it added some pieces to your knowledge stack! Before you go, if you enjoyed reading this article:
👉 Be sure to clap and follow me, and let me know if any feedback.
👉I built versatile Generative AI applications using the Large Language Model (LLM), covered advanced RAG concepts, and serverless AWS architectures for Big Data processing. You’re welcome to take a look at the repo and star⭐it.
- ⭐ Generative AI applications Repository
- ⭐ Advanced RAG applications Repository
- ⭐ Serverless AWS architectures Repository
