Data Management in LlamaIndex🦙: Smart Tracking and Debugging of Document Changes
Efficient Document Tracing and Debugging
Welcome to the Advanced RAG 📚Learning Series!
Dive deeper into the fascinating world of Retrieval-Augmented Generation with this comprehensive series of articles. This series delves into cutting-edge techniques and strategies to elevate your understanding and mastery of RAG applications. Explore the following articles to enhance your skills and Stay tuned 🔔 for more articles in this series as we continue to delve deeper into the world of Advanced RAG and unlock its boundless potential.
Don’t miss out on any discoveries! Bookmark🏷️ this article and check back often for the latest installments in this exciting learning series.
Topics covered so far:
- Optimizing Retrieval with Additional Context & MetaData using LlamaIndex
- Enhancing Retrieval Efficiency through Rerankers using LlamaIndex
- Query Augmentation for Next-Level Search using LlamaIndex
- Smart Tracking and Debugging of Document Changes using LlamaIndex (you are here!)

In the world of handling private information, dealing with the constant changes in our data sources can be tricky. As we explore more ways to use RAG-based applications with different types of documents, questions arise about making sure it understands new content, managing changes in existing documents, and not giving outdated information from deleted documents.
The challenge lies in adapting to the ever-shifting nature of our private data sources efficiently. This is where LlamaIndex document management steps in to provide a smart solution.
In this blog post, we’ll take a closer look at how LlamaIndex tackles the complexities of changing data sources, ensuring accurate and quick information retrieval even as things keep evolving.
Say ‘No’ to Reindexing Fatigue
Indexing data repeatedly can increase costs in RAG-based applications. Here’s why:
- Token Consumption: RAG applications rely on tokens to process and interact with data. Every time you reload, re-embed, and re-index your data, you consume tokens. This can accumulate quickly, especially with large private data sources.
- Computational Resources: Reindexing involves significant computational power to process and structure the data. Frequent reindexing demands more resources from your infrastructure, leading to higher operating costs.
- Time & Efficiency: Reindexing takes time! Each iteration means your application is unavailable and users might experience delays. This impacts overall efficiency and user experience.
To mitigate these challenges and control costs, it’s essential to implement efficient indexing strategies to strike a balance between maintaining data freshness and managing resource utilization effectively.
Let’s uncover the features that make LlamaIndex stand out in managing and adapting to the constant changes in your data.
1.1 Load Data
1.2 Refresh
1.2.1 Dissecting the docstore.json
1.3 Delete
1.4 Update
Document Management in LlamaIndex
LlamaIndex relies on three pivotal data structures — index struct, doc store, and vector store to proficiently manage documents.
Index Struct
The index struct is a fundamental data structure that serves as an organized and searchable reference to the documents within LlamaIndex. It contains information about the location and characteristics of documents, enabling rapid and efficient retrieval.
Doc Store (Document Store)
The docstore is a storage system specifically designed for holding the actual documents or content. It stores the raw text, metadata, or any other relevant information associated with each document.
This data structure acts as the repository for the content that the index struct points to, ensuring that the actual document details are readily available when needed.
As soon as you persist your indexes to any form of storage, the
docstore.jsonfile will be generated.
Vector Store
When we employ a vector index, a vector store comes into play. A vector index involves representing documents as vectors in a multi-dimensional space, allowing for similarity comparisons and advanced search functionalities.
The vector store holds these vector representations, facilitating efficient similarity searches and retrieval based on the spatial relationships between documents.
Defining Documents
Documents can either be created automatically via data loaders or constructed manually. By default, all of the data loaders return Document objects through the load_data function.
Significance of doc_id and ref_doc_id
Connecting a docstoreto the ingestion, pipeline makes document management possible. The doc_id is used to enable the efficient refreshing of documents in the index. When using SimpleDirectoryReader, you can automatically set the doc doc_id to be the full path to each document.
Note: the ID can also be set through the node_id or id_ property on a Document object.
By using either document.doc_id or node.ref_doc_id as a reference point, the ingestion pipeline actively checks for duplicate documents. Here’s how it operates:
- It maintains a map
linking doc_idtodocument_hash. - When a duplicate
doc_idis identified, andhashhas been altered, the document undergoes re-processing. - If the
hashremains unchanged, the document is skipped in the pipeline.
Document Management in Action
You can follow alongside by clicking on the Link to the GitHub code repository
1. Load Data
Accessing Google Drive from Google Colab
You can use the drive module from google.colab to mount your entire Google Drive to Colab by:
from google.colab import drive
drive.mount('/content/gdrive')
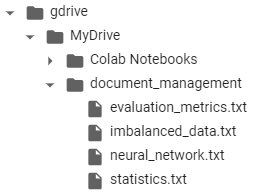
!ls '/content/gdrive/MyDrive/document_management/'
files_path = '/content/gdrive/MyDrive/document_management/'
index_persist_dir = './storage/document_management/'
try:
storage_context = StorageContext.from_defaults(persist_dir=index_persist_dir)
index = load_index_from_storage(storage_context)
print('loading from disk')
except:
documents = SimpleDirectoryReader(files_path, filename_as_id=True).load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
index.storage_context.persist(persist_dir=index_persist_dir)
print('persisting to disk')1.1 Checking File Contents: Let’s list the contents of a specific directory in Google Drive to confirm the presence of files to be indexed.
1.2 Setting Paths: Defines two key paths:
files_path: The location of the documents to be indexed.index_persist_dir: The directory where the index will be stored for future use.
1.3 Loading or Creating Index: It attempts to load an existing index from the storage directory to save processing time. If no index is found, it proceeds to create a new one by reading the documents from the files_path using a SimpleDirectoryReader. Then, it creates a VectorStoreIndex from those documents, preparing for efficient search and retrieval. Finally, persists (saves) the newly created index to the storage path for future use.
Let’s do a sanity check to ensure what documents the index has ingested. Each index has a ref_doc_info property which is a kind of mapping to the original doc IDs that we input.
print('ref_docs ingested: ', len(index.ref_doc_info))
print('number of input documents: ', len(documents))
ref_docs ingested: 4
number of input documents: 4So, the index is properly inserted in all our documents.
Let’s load the index that we persisted/stored. You can also store it in any of the Vector Database and load it from there. Then, double-check to ensure the original number of documents are stored in the Memory or Vector Database.
index = load_index_from_storage(StorageContext.from_defaults(persist_dir=index_persist_dir),
service_context=service_context)
print('ref_docs ingested: ', len(index.ref_doc_info))
print('number of input documents: ', len(documents))
**********
Trace: index_construction
**********
ref_docs ingested: 4
number of input documents: 4Question: Let’s check a random question related to Andrew Huberman’s sleep podcast for which there is NO information present in the Vector DataStore yet.
query_input = "How music can help in sleep?"
response = index.as_query_engine().query(query_input)
from llama_index.response.pprint_utils import pprint_response
pprint_response(response, show_source=True)Response:
Examine the below response and identify the top nodes' content with low similarity scores. The nodes' text pertains to the Neural Network, while the query is related to sleep. This situation is indicative of hallucination, where the model is fabricating an answer unrelated to the query.

Also, let’s confirm by checking thedoc_id of the documents present in VectorStore. You will see that there is NO andrew_sleep.txt document present yet.
for doc_num in range(len(documents)):
print(f"document-{doc_num} --> {documents[doc_num].id_}")
If you want to debug further i.e. what was sent to LLM as a prompt and what it returned. Look at the Tracing and Debugging section.
2. Refresh
By assigning a unique doc_id to each document during the data loading process, you gain the ability to seamlessly update your index through the use of the refresh() function.
This function selectively updates documents that share the same
doc_idbut have different text contents. Furthermore, any documents absent from the index entirely will be seamlessly inserted during the refresh process.
As an additional benefit, the refresh() function provides a boolean list, offering insights into which documents from the input have been successfully refreshed within the index.
This straightforward approach ensures efficient and targeted updates to your index based on unique document identifiers.
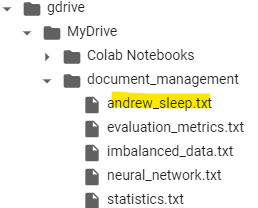
Let’s add andrew_huberman_sleep.txt and see how it responds:
# reading files again
documents = SimpleDirectoryReader(files_path, filename_as_id=True).load_data()
print(f"Loaded {len(documents)} docs")
<<Loaded 5 docs>># Run refresh_ref_docs method to check for document updates
refreshed_docs = index.refresh_ref_docs(documents)
print(refreshed_docs, "\n")
print('Number of newly inserted/refreshed docs: ', sum(refreshed_docs))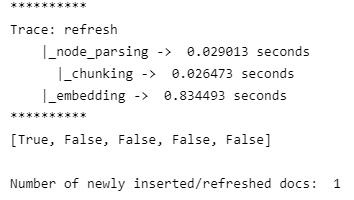
Since, we have added the new document andrew_huberman_sleep.txt, the number of newly inserted/refreshed docs equal to 1
Question: Let’s again ask the earlier question related to Andrew Huberman’s sleep podcast.
query_input = "How music can help in sleep?"
response = index.as_query_engine().query(query_input)
from llama_index.response.pprint_utils import pprint_response
pprint_response(response, show_source=True)Response: Voila! Examine the response and identify the top nodes’ content with higher similarity scores. Now, the nodes’ text pertains to the sleep podcast text, which is very well correlated with our query.

Also, let’s confirm by checking doc_id each of the documents present. You will see that andrew_sleep.txt the document is present now.
for doc_num in range(len(documents)):
print(f"document-{doc_num} --> {documents[doc_num].id_}")
Let’s look at the index.ref_doc_info to find out the doc_id and RefDocInfo
info_dict = index.ref_doc_info
info_dict
Insights: Every document (identified by doc_id) has a RefDocInfo that holds all the parsed nodes from that document. For example, the document evaluation_metrics.txt has been parsed into 5 nodes. Customizing metadata for each document is possible and can be tailored to your specific use case. For additional guidance, refer to this comprehensive guide.
Dissecting the docstore.json
For indexes, by leveraging the docstore.json, you gain the capability to view the documents you’ve inserted. The output displays entries with ingested doc ids as keys, along with their corresponding node_ids indicating the nodes they were split into. Additionally, the original metadata dictionary of each input document can also be tracked for comprehensive visibility into the stored information.
The docstore.jsonmaintains a map linking doc_id to document_hash. When a duplicate doc_id is identified, and hash has been altered, the document undergoes re-processing. If the hash remains unchanged, the document is skipped in the pipeline. When you update/delete any part of this document, the document_hash will be updated with the next index refresh.
It contains reference document information (ref_doc_info), metadata providing additional details about each document, and the actual textual content or data that the model uses for retrieval and generation. These components collectively enable the RAG model to effectively navigate and utilize the stored documents during the retrieval process.
Let’s look at each of the components:
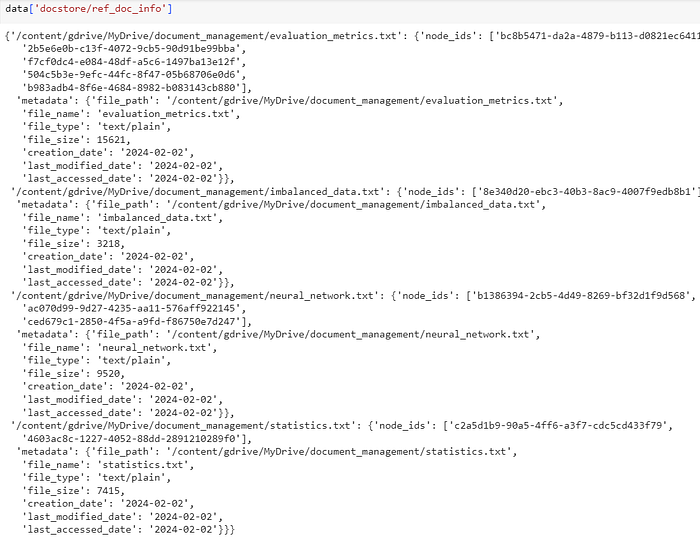
- Ref_doc_info
- It refers to the reference document information associated with each document in the docstore.
- It typically includes details about how the document is tokenized, its embeddings, and any other information necessary for retrieval.
- This information is crucial for the model to effectively retrieve relevant content during the generation phase.
data['docstore/ref_doc_info']Same as index.ref_doc_info
2. metadata
- It encompasses additional information about each document beyond its textual content.
- This could include attributes such as the document’s title, author, publication date, or any other relevant metadata.
- Metadata is valuable for providing context and additional details about the documents stored in the docstore.
data['docstore/metadata']
document_hash for evaluation_metrics.txt document3. data
- It refers to the actual content of the documents. This could include the original text or any other textual information that the model uses for retrieval and generation.
data['docstore/data']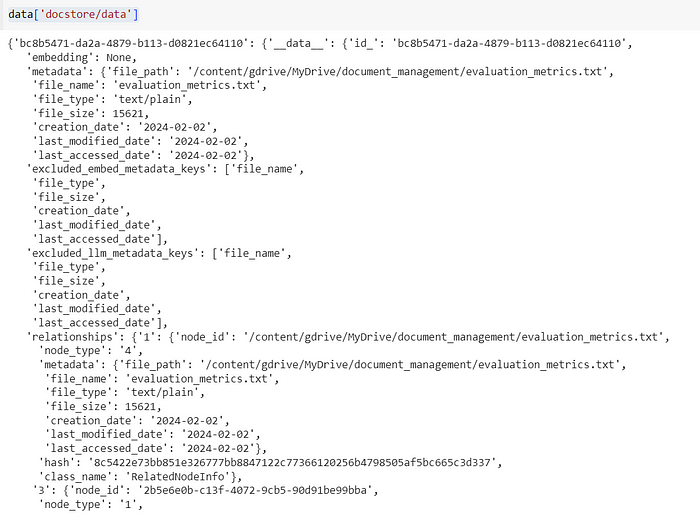
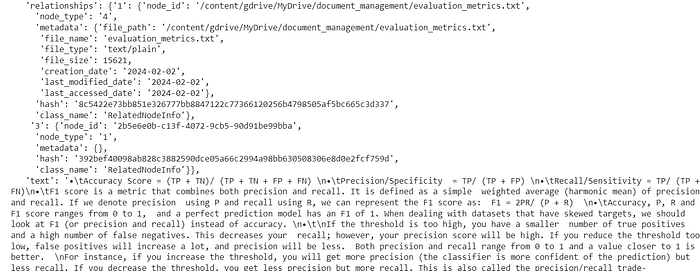
3. Delete
Deleting a document from the index is a straightforward process. It can be done by specifying the doc_id. Upon deletion, all nodes associated with the specified document are removed.
index.delete_ref_doc("/content/gdrive/MyDrive/document_management/imbalanced_data.txt", delete_from_docstore=True)
Let’s double-check:
for doc_num in range(len(documents)):
print(f"document-{doc_num} --> {documents[doc_num].id_}")
Question: Let’s again ask the question related to the deleted document imbalanced_data.txt.
query_input = "What are the various techniques mentioned in the document to handle imbalanced data?"
response = index.as_query_engine().query(query_input)Response: Examine the response and identify the top nodes’ content (surprisingly we have a slightly higher similarity score) but the nodes’ text pertains to the evaluation metric MAE which is coming from evaluation_metrics.txt. This situation is indicative of hallucination, where the model is fabricating an answer unrelated to the query.

4. Update
To modify information within an index, you can perform an update on a document with the same doc_id if it is already present. This allows you to seamlessly incorporate changes to the document, ensuring that the updated information is reflected within the index.
Now, I have updated(appended) the text in neural_network.txt with the content fromimbalanced_data.txt.
documents = SimpleDirectoryReader(files_path, filename_as_id=True).load_data()
print(f"Loaded {len(documents)} docs")
<<Loaded 4 docs>>
# Run refresh_ref_docs method to check for document updates
refreshed_docs = index.refresh_ref_docs(documents)
print(refreshed_docs, "\n")
print('Number of newly inserted/refreshed docs: ', sum(refreshed_docs))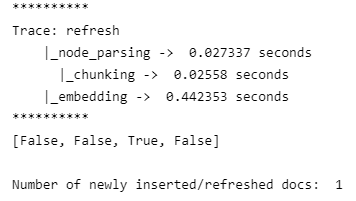
Question: Let’s again ask the question related to the imbalanced_data whose text has been updated in the neural_network.txt.
query_input = "What is SMOTE technique mentioned in the document to handle imbalanced data?"
response = index.as_query_engine().query(query_input)
from llama_index.response.pprint_utils import pprint_response
pprint_response(response, show_source=True)Response: Better response!

Note: You can try updating the document towards the start, middle, or end and compare the responses.
Tracing and Debugging
Let’s debug further using basic logging.This can be done anywhere in your application like this:
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))Llama Debug Handler
Now, we will learn how we can debug our queries in LlamaIndex more efficiently. Each query undergoes distinct stages within LlamaIndex before delivering the final response. Understanding these steps, including the time taken by each subprocess, can significantly improve the debugging process.
Beyond queries, data ingestion in LlamaIndex experiences various stages before becoming available for querying. The key advantages of effective debugging are:
- Verify the time consumed by each subprocess easily.
- Identify processes that contribute more or less time during query operations.
- Examine the values held by these subprocesses at different stages, both during Data Ingestion and Query operations.
What makes this debugging process even more accessible is that there’s no need for an external library or tool. LlamaIndex itself provides a debugging solution through a feature known as the Llama Debug Handler.
Let’s explore how to leverage this feature in code to gain a deeper understanding of its capabilities.
Callback Management
LlamaIndex offers a robust callback system designed to facilitate debugging, monitoring, and tracing the library’s internal processes. Beyond logging event-related data, we can monitor the duration and frequency of each occurrence. Additionally, a trace map of events is maintained, providing callbacks the flexibility to utilize this data as needed.
For instance, the default behavior of LlamaDebugHandler involves printing the trace of events after most operations. Obtaining a straightforward callback handler can be achieved as follows:
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
import nest_asyncio
nest_asyncio.apply()
# Using the LlamaDebugHandler to print the trace of the underlying steps
# regarding each sub-process for document ingestion part
llama_debug = LlamaDebugHandler(print_trace_on_end=True)
callback_manager = CallbackManager([llama_debug])
# ServiceContext
# Service context contains information about which LLM we
# are going to use for response generation and which
# embedding model to create embeddings
service_context = ServiceContext.from_defaults(llm=llm,
embed_model=embed_model,
callback_manager=callback_manager
)Let’s check out the logs to debug what happens when we query our document using LlamaIndex.
query_input = "How music can help in sleep?"
response = index.as_query_engine().query(query_input)After running this piece of code you’ll see what happens when you query your data.
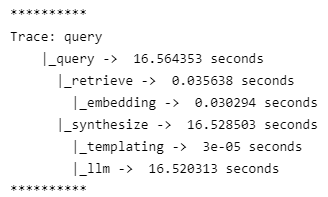
Isn’t it great! Every part of the process is shown as logs for you to debug if there is any issue in your case.
Llama Debug Handler not only shows the time for each process. In fact, at any time of the process, you can check and debug every process and find out what is going on here.
For example, If you want to check how many LLM calls you have made until the file is running, You can do that simply by adding this line of code at the end of the above code.
# Print info on the LLM calls during the list index query
print(llama_debug.get_event_time_info(CBEventType.LLM))
# Output on the terminal will be like this
EventStats(total_secs=1.509315, average_secs=1.509315, total_count=1)If you want to check what was sent to LLM and what LLM returned, You can do that by simply adding this line of code at the bottom.
# Print info on llm inputs/outputs - returns start/end events for each LLM call
event_pairs = llama_debug.get_llm_inputs_outputs()
print(event_pairs[0][0]) # Shows what was sent to LLM
print(event_pairs[0][1].payload.keys()) # What other things you can debug by simply passing the key
print(event_pairs[0][1].payload["completion"]) # Shows the LLM response it generated.Let’s look at the Payloadsent to LLM regarding our Sleep/Music query:
# Look at the Payload prompt sent to LLM
# It has no mention of Sleep/Music etc.
event_pairs[0][0].payload['formatted_prompt']
Let’s look at the Response(Completion)from the LLM :
# clearly a case of halluciniation
print(event_pairs[0][1].payload["completion"]) # Shows the LLM response it generated.
Response(Completion)Llama Debug Handler not only contains information about the current state of LLM but there’s a lot more that you can do with it. For example, You can debug the following other parts the same way we did for the LLM one.
- CBEventType.LLM
- CBEventType.EMBEDDING
- CBEventType.CHUNKING
- CBEventType.NODE_PARSING
- CBEventType.RETRIEVE
- CBEventType.SYNTHESIZE
- CBEventType.TREE
- CBEventType.QUERY
Refer to LlamaIndex for more information.
Key Takeaways
- LlamaIndex relies on three pivotal data structures —
index struct,doc store, andvector store(if utilizing a vector index) — to proficiently manage documents. - Constantly Refreshing Data: LlamaIndex showcases its adaptability by efficiently indexing and continuously refreshing data, making it a versatile and dynamic document management tool.
- Enhancing Efficiency: Leveraging document management tools like LlamaIndex proves invaluable for organizing and analyzing large datasets, contributing to time savings and increased operational efficiency.
- Time and Token Savings: Saving and loading indexes can save time and tokens when working with document management systems.
- Importance of Regular Updates: The significance of regularly updating and managing document indexes for staying current and relevant.
- Caution in Deletion: While LlamaIndex offers the capability to update and insert documents based on content changes or new doc IDs, caution is advised when deleting from the doc store to prevent unintended consequences.
Refer to the complete code on Github:
To refer to other advanced RAG methods, refer to this repo:
Reference
- https://docs.llamaindex.ai/en/stable/examples/ingestion/document_management_pipeline.html
- https://docs.llamaindex.ai/en/stable/understanding/tracing_and_debugging/tracing_and_debugging.html#basic-logging
- https://docs.llamaindex.ai/en/stable/module_guides/loading/documents_and_nodes/usage_documents.html
Thank you for reading this article, I hope it added some pieces to your knowledge stack! Before you go, if you enjoyed reading this article:
👉 Be sure to clap and follow me, and let me know if any feedback.
👉I built versatile Generative AI applications using the Large Language Model (LLM), covered advanced RAG concepts, and serverless AWS architectures for Big Data processing. You’re welcome to take a look at the repo and star⭐it.
- ⭐ Generative AI applications Repository
- ⭐ Advanced RAG applications Repository
- ⭐ Serverless AWS architectures Repository
